Projets
- Genie Electritque et Telecom
- Prévision
- Optimisation déterministe
- Optimisation stochastique
- Apprentissage par renforcement
- Data Engineering & MLOps
- Traitement naturel du langage & LLM
- Appprentissage profond & Vision par ordinateur
Cette page regroupe mes projets techniques organisés par domaine de spécialisation.
Chaque section présente des projets sélectionnés avec leur contexte, approche méthodologique, résultats et liens vers le code lorsque disponible.
Télécom & Génie Électrique
Conception et optimisation de systèmes de communication sans fil, avec un accent particulier sur l’application des techniques d’apprentissage automatique pour améliorer la performance et la robustesse des réseaux dans des environnements contraints.
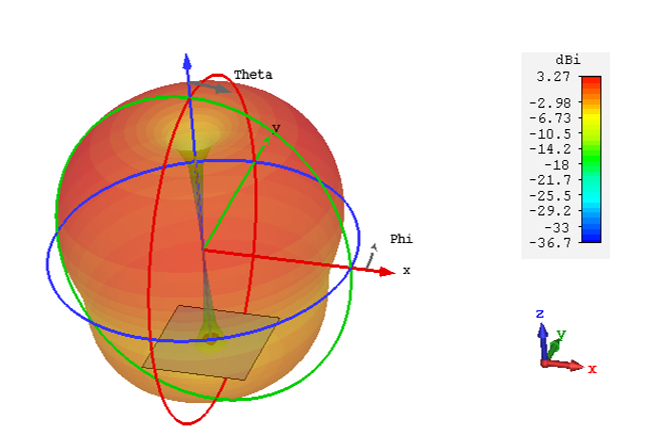
P1 - Optimisation du beamforming d’un réseau planaire d’antennes par Réseaux de Neurones (RNA)
Contexte.
Conception d’une antenne intelligente planaire (réseau 4×5 monopôles) et apprentissage d’un perceptron multicouche (PMC/MLP) pour prédire la loi d’alimentation (amplitudes/phases) afin de former un faisceau dans une direction cible.
Approche.
- Baseline analytique : Dolph–Tchebychev (contrôle des lobes secondaires).
- Modèle ML : RNA / PMC avec rétropropagation, critère EQM (MSE).
- Chaîne d’évaluation : MATLAB (NNSTART) → CST Microwave Studio (co-simulation et pilotage).
Résultats clés.
- Gain de directivité ≈ +0,2 dB par rapport à la méthode de Dolph–Tchebychev.
- Temps de calcul ≈ 1,27 s pour la génération de la loi d’alimentation.
- Temps d’apprentissage du réseau : ≈ 27 h 59 min 58 s (backpropagation).
Technologies.
MATLAB R2018a · Neural Network Toolbox (NNSTART) · CST Microwave Studio · Antennes réseau · Beamforming · Optimisation heuristique · MLP
Livrables.
- Rapport technique détaillé (Article scientifique)
- Scripts MATLAB (apprentissage et inférence)
- Modèles et simulations électromagnétiques sous CST
- Diagrammes de rayonnement 2D et 3D
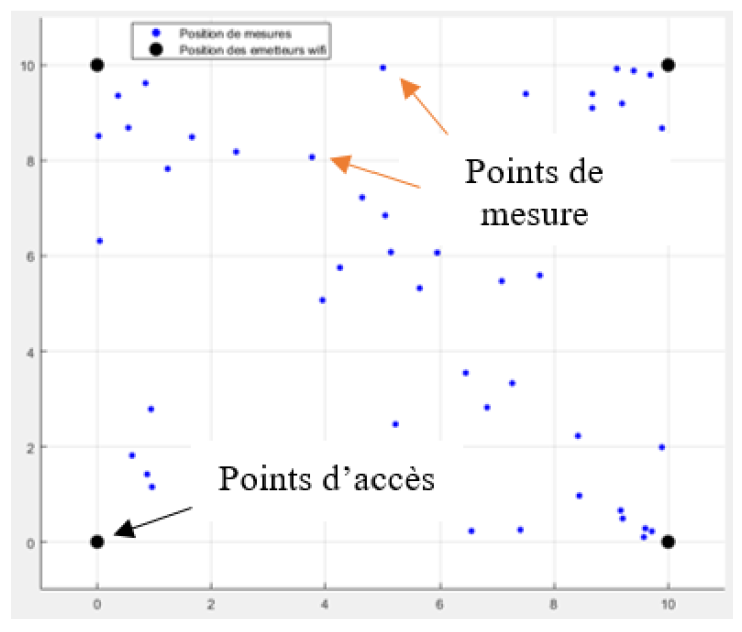
P2 - Localisation indoor Wi-Fi par fingerprinting RSSI
Comparaison Machine Learning (RNA/MLP) vs PSO
Résumé.
Prototype de localisation indoor dans une zone 10 m × 10 m avec 4 points d’accès Wi-Fi.
J’ai formulé le problème comme une régression supervisée : ((RSSI_1,,RSSI_4)(x,y)), puis comparé un réseau de neurones (MLP) à un PSO en précision et en latence.
Objectif.
- Estimer la position (x, y) à partir des RSSI Wi-Fi (fingerprinting)
- Optimiser le compromis précision / temps de calcul (contrainte télécom temps-réel)
Méthodologie.
- Cadre expérimental : zone 100 m², 2.4 GHz, 4 AP aux coins
- Dataset : 50 points de référence (base fingerprinting)
- Modèle ML : MLP (RNA), régression, loss MSE
- Baseline : PSO (60 particules, (c_1=c_2=2), (w), 1000 itérations)
- Condition : LOS (protocole contrôlé)
Résultats clés.
- RNA (MLP) : 2.5729 m d’erreur moyenne | 0.206288 s
- PSO : 2.8612 m d’erreur moyenne | 1.360301 s
- Gain RNA : ≈ +11% plus précis | ≈ ×6.6 plus rapide (inférence)
Stack & compétences.
- Fingerprinting Wi-Fi (RSSI), propagation radio (FSPL/Friis)
- Régression supervisée, MLP, MSE, évaluation
- PSO (paramétrage, convergence, coût calcul)
- MATLAB + reporting LaTeX
Prévision
Développement de dispositifs de prévision temporelle appliqués à des systèmes énergétiques réels, avec un accent particulier sur la robustesse statistique, la prise en compte de variables exogènes et la comparaison rigoureuse entre approches classiques et modèles d’apprentissage profond.

P1 — Prévision de la consommation énergétique régionale (approche statistique)
Contexte
Projet de prévision de la consommation énergétique journalière (charge de pointe) pour les régions desservies par JCP&L (New Jersey), dans un contexte de planification énergétique à moyen terme.
L’objectif est d’anticiper les fluctuations de la demande tout en conservant une interprétabilité élevée des mécanismes explicatifs.
Approche méthodologique
La démarche repose sur une modélisation temporelle classique (Naïf, ETS, SARIMAX) intégrant explicitement :
- la saisonnalité énergétique,
- les tendances de long terme,
- des variables exogènes climatiques et socio-démographiques.
Les modèles sont évalués dans un cadre strict de validation temporelle glissante, garantissant une estimation réaliste des performances hors échantillon.
Résultats clés
- Prévisions stables et cohérentes à l’échelle régionale
- Identification claire des composantes saisonnières et des effets exogènes
- Construction d’une baseline opérationnelle fiable
Valeur ajoutée
Ce projet illustre l’intérêt des modèles statistiques bien spécifiés pour la prise de décision énergétique et la planification opérationnelle, lorsque la transparence et la traçabilité des hypothèses sont essentielles.
Tech: R · Prévision statistique · Séries temporelles · Power BI · Tableau

P2 — Prévision énergétique multivariée par apprentissage profond
Contexte
Extension du projet précédent vers une approche data-driven, visant à capturer des relations non linéaires complexes entre consommation énergétique, conditions climatiques et dynamiques régionales.
Le cadre est celui d’une prévision multirégionale, à l’échelle des régions administratives québécoises, caractérisées par des comportements hétérogènes et des séries partiellement non stationnaires.
Approche méthodologique
La modélisation s’appuie sur des architectures séquentielles (RNN-LSTM, TCN), comparées systématiquement à des modèles statistiques traditionnels (SARIMA), afin de :
- exploiter des fenêtres temporelles glissantes,
- intégrer des transformations stabilisatrices de la variable cible,
- apprendre automatiquement les dépendances dynamiques entre variables.
Une attention particulière est portée à l’évaluation comparative des approches afin de mesurer le gain réel apporté par l’apprentissage profond.
Résultats clés
- Amélioration des performances sur certaines régions à forte variabilité
- Meilleure capture des effets retardés et des non-linéarités
- Comportement robuste sur des périodes récentes hors échantillon
- Confirmation de la pertinence persistante des modèles statistiques traditionnels
Valeur ajoutée
Ce travail met en évidence les forces et limites du deep learning appliqué à la prévision énergétique, et propose un cadre pragmatique pour arbitrer entre performance prédictive, stabilité temporelle et complexité opérationnelle.
Tech: Python · Pytorch · TensorFlow · Scikit-learn · Pandas · NumPy · Matplotlib · Power BI
Optimisation déterministe
Conception et analyse de modèles d’optimisation déterministes pour des problèmes réels de planification, d’allocation de ressources et de gestion de projets, avec un accent particulier sur la traduction des contraintes opérationnelles en formulations mathématiques exploitables et sur l’analyse des compromis coût–temps–ressources.
P1 — Optimisation déterministe intégrée d’un entrepôt logistique (MILP)
Contexte
Projet industriel récent visant l’optimisation opérationnelle d’un entrepôt logistique multi-zones, multi-formats et multi-niveaux, dans un contexte réel de forte variabilité des flux, de contraintes physiques strictes et de pression opérationnelle quotidienne.
Le projet est conduit dans un cadre confidentiel ; les éléments présentés ici sont volontairement abstraits et anonymisés.
L’objectif global est d’améliorer simultanément :
- l’efficacité des placements en stock,
- la performance de la préparation de commandes,
- et la cohérence des réapprovisionnements internes,
tout en maintenant la faisabilité opérationnelle jour après jour.
Approche méthodologique
Le problème est formulé comme une optimisation déterministe séquentielle structurée autour de trois sous-modèles complémentaires :
- Placement (Putaway / Slotting) : décisions d’activation de formats par emplacement et allocation des arrivages entrants, sous contraintes de capacité, compatibilité et proximité fonctionnelle.
- Préparation de commandes (Picking) : allocation optimale des prélèvements afin de maximiser le service tout en minimisant les déplacements internes.
- Réapprovisionnement interne (Replenishment) : relocalisation contrôlée des stocks via un sous-ensemble d’arcs admissibles, afin de limiter la combinatoire et les coûts de mouvement.
Ces modèles sont orchestrés séquentiellement à l’échelle journalière, avec propagation cohérente des états d’inventaire entre étapes.
Évaluation et indicateurs de performance
Un moteur d’indicateurs permet d’évaluer l’impact des décisions avant et après chaque étape, notamment :
- distance moyenne pondérée au point central,
- taux d’occupation et dispersion des stocks,
- pénalités de co-localisation (similarité),
- volume et coût des mouvements internes,
- stabilité du layout (churn).
Cette approche permet une lecture quantitative claire des compromis opérationnels induits par chaque décision.
Résultats clés
- Amélioration mesurable de l’accessibilité des articles à forte demande
- Réduction des déplacements internes inutiles
- Meilleure stabilité du layout sous flux dynamiques
- Cadre reproductible pour tester des scénarios opérationnels réalistes
Valeur ajoutée
Ce projet illustre une mise en œuvre complète de l’optimisation déterministe appliquée à un système logistique réel, combinant modélisation mathématique, orchestration décisionnelle et analyse de performance.
Il constitue une base solide pour des extensions futures vers des approches stochastiques ou apprentissage par renforcement, tout en restant exploitable opérationnellement.
Tech: Python · GulP/Gurobi · Plotly · NetworkX · Pandas · NumPy · Matplotlib · Power BI
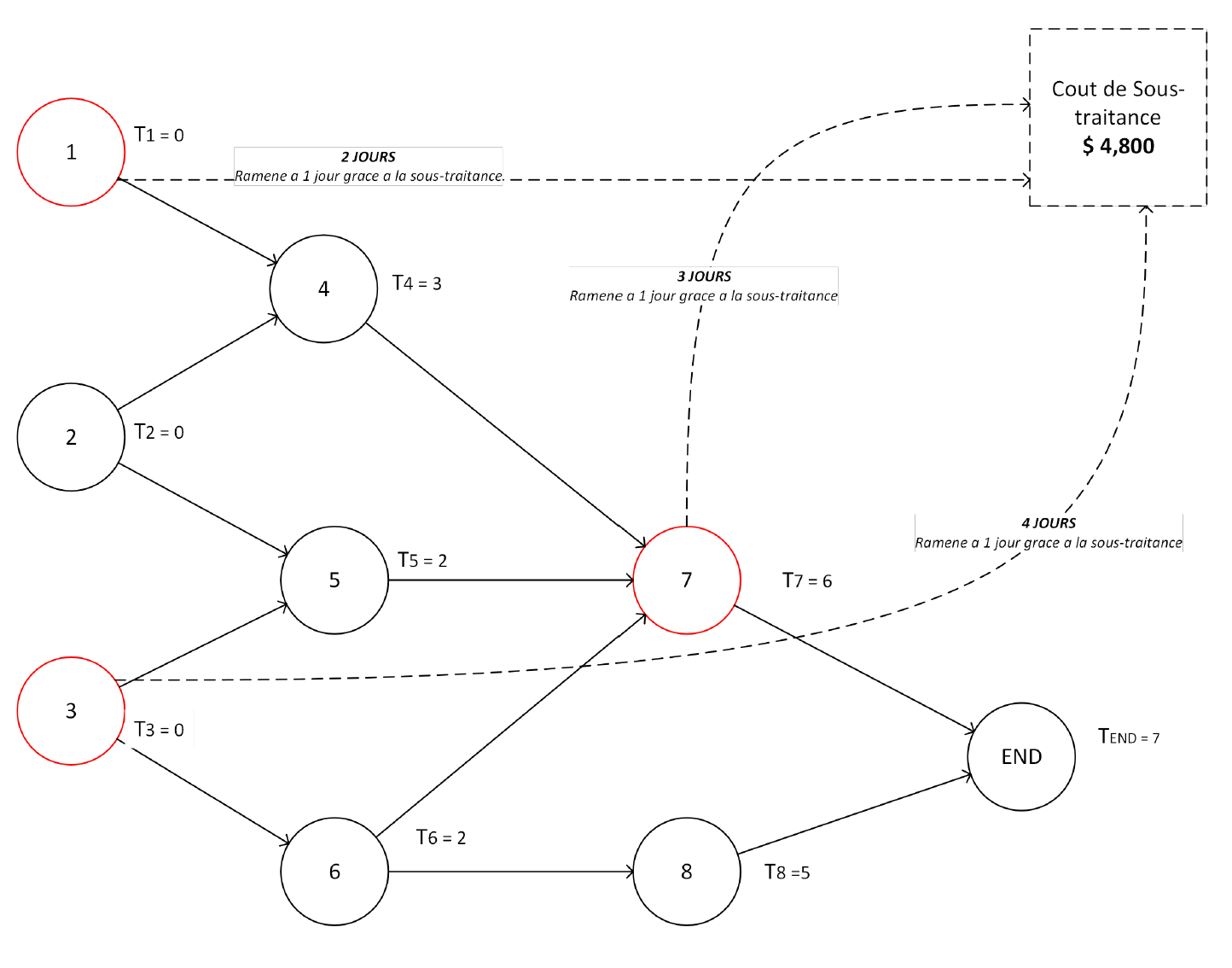
P2 — Ordonnancement et accélération d’un projet logiciel complexe
Contexte
Problème de planification du développement d’un logiciel composé de plusieurs sous-projets interdépendants, avec des contraintes strictes de précédence.
L’objectif initial est de minimiser la durée totale du projet, puis d’explorer des stratégies d’accélération sous contraintes budgétaires, en intégrant des décisions d’externalisation partielle ou totale.
Approche méthodologique
Le problème est formulé comme un modèle d’ordonnancement déterministe, enrichi progressivement par : - des contraintes de précédence explicites entre tâches, - des variables de décision binaires pour représenter l’externalisation, - des contraintes de délai global imposées par le client, - des mécanismes linéaires pour modéliser des coûts non uniformes, des rabais conditionnels et des seuils de livraison partielle (ex. 75 % des tâches livrées avant une date cible).
Chaque ajustement du modèle vise à conserver la linéarité, tout en augmentant le réalisme décisionnel.
Résultats clés
- Réduction significative du délai de livraison sous contraintes de coût
- Identification des tâches critiques à externaliser en priorité
- Analyse fine des compromis entre coût d’accélération et respect des échéances
Valeur ajoutée
Ce projet illustre une démarche complète de modélisation incrémentale, typique des contextes industriels réels, où les exigences évoluent et nécessitent des modèles robustes, explicables et adaptables.
Tech: Excel Solver · Gams · IBM Cplex · PowerBi
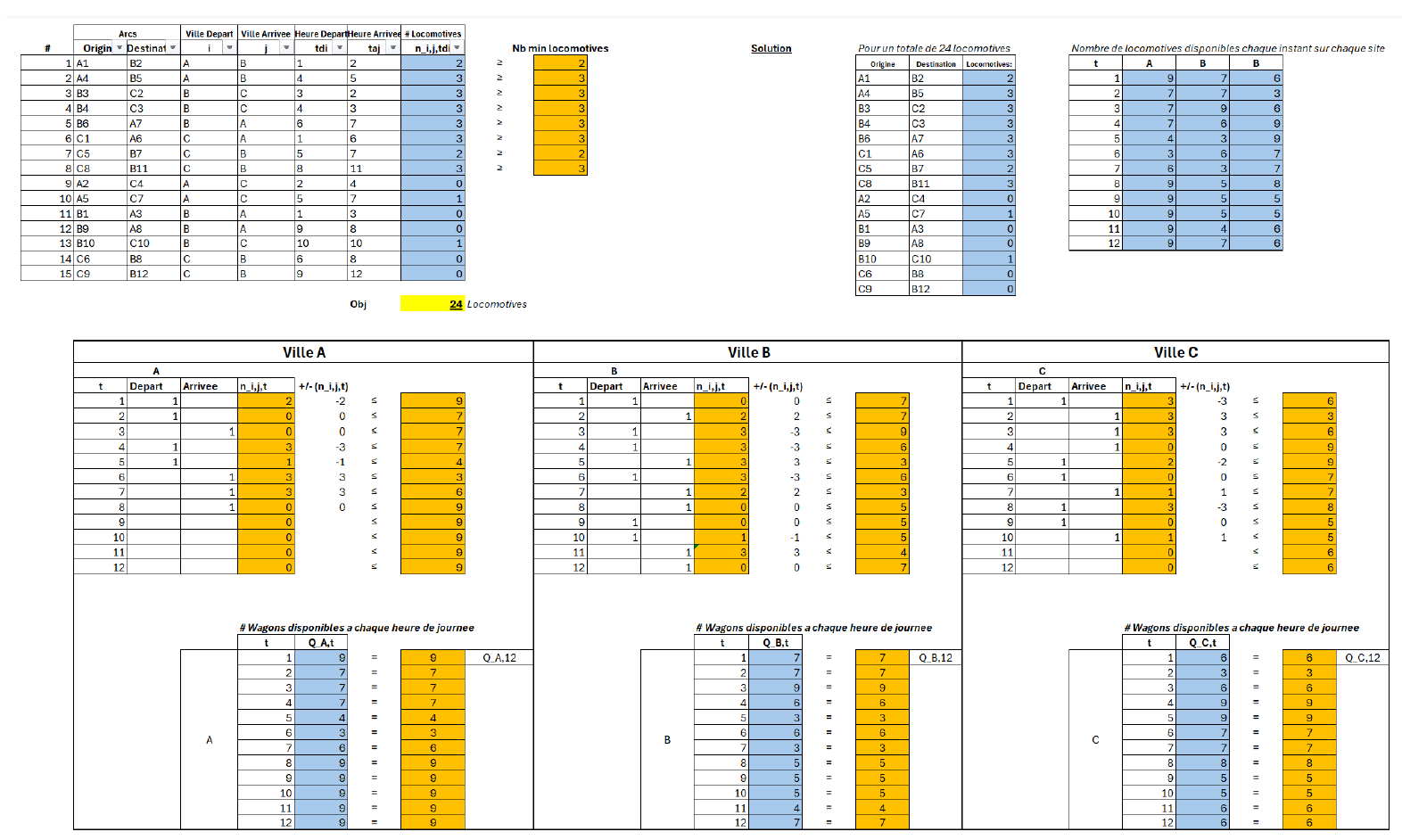
P3 — Allocation dynamique d’un parc de locomotives multi-sites
Contexte
Problème de gestion d’un parc de locomotives circulant entre plusieurs sites interconnectés (A–B–C), avec des horaires de départ et d’arrivée imposés et des exigences minimales de capacité par trajet.
L’enjeu est de minimiser le nombre total de locomotives nécessaires, tout en assurant la faisabilité opérationnelle du réseau.
Approche méthodologique
Le système est modélisé comme un problème d’allocation déterministe multi-périodes, intégrant : - des contraintes de capacité minimale par trajet, - des équations de balance des flux garantissant la cohérence des disponibilités par site, - des conditions cycliques assurant la stabilité du parc sur l’horizon temporel.
Le modèle capture explicitement la dynamique temporelle des ressources et les interdépendances entre décisions locales et globales.
Résultats clés
- Détermination du parc minimal nécessaire pour satisfaire l’ensemble des trajets
- Visualisation claire des flux et des tensions sur les ressources
- Mise en évidence des périodes critiques en termes de disponibilité
Valeur ajoutée
Ce travail met en lumière la puissance des modèles déterministes pour la planification de réseaux logistiques, lorsque la priorité est donnée à la robustesse et à la faisabilité plutôt qu’à la stochasticité.
Tech: Python · Gams · IBM Cplex · PowerBi · Excel Solver
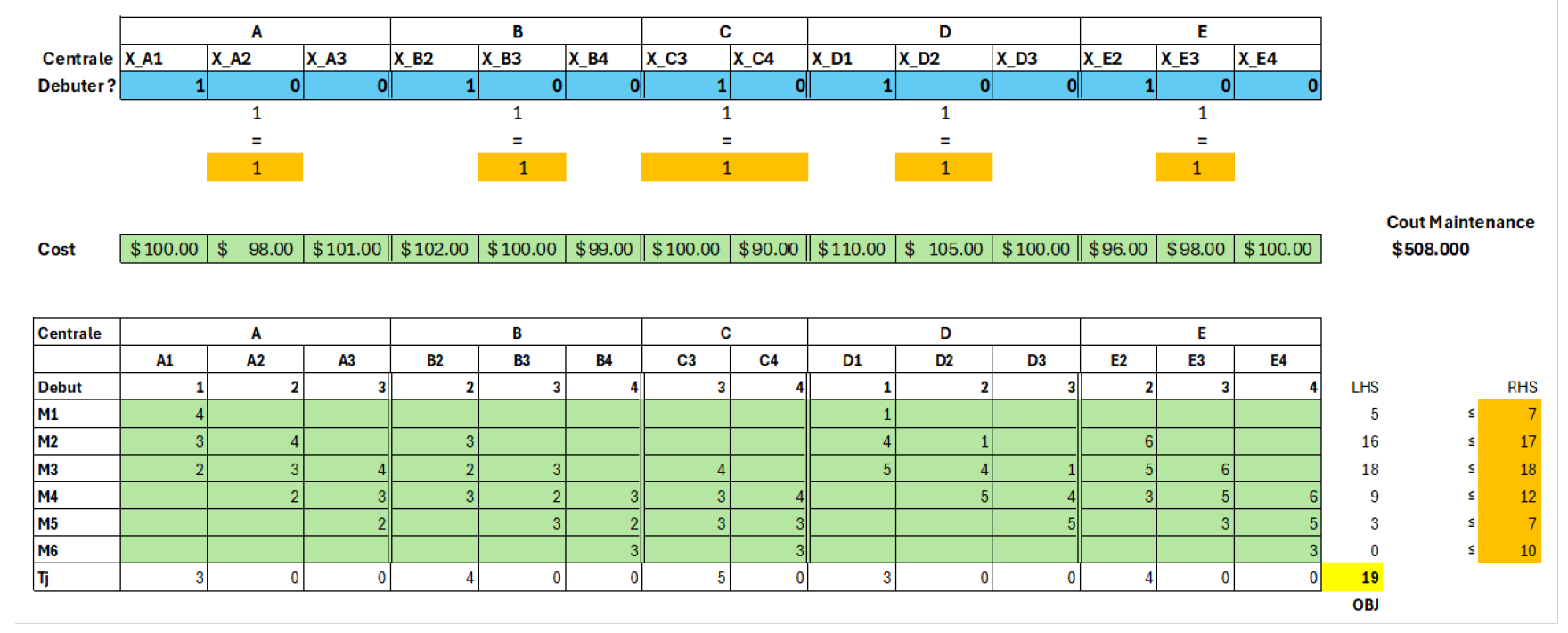
P4 — Planification optimale de la maintenance de centrales électriques
Contexte
Problème de planification de la maintenance de plusieurs centrales électriques sur un horizon de plusieurs mois, sous contraintes de disponibilité des équipes, de fenêtres de lancement autorisées et de coûts dépendants du calendrier.
Deux objectifs sont étudiés : la minimisation du coût total et la fin des maintenances le plus tôt possible, indépendamment du budget.
Approche méthodologique
Le problème est formulé comme un modèle d’optimisation linéaire en variables binaires, intégrant : - des contraintes d’unicité du mois de démarrage par centrale, - des contraintes globales de capacité en personnel par période, - des relations temporelles liant le mois de démarrage à la date de fin, - des ajustements imposant des relations d’ordre ou de synchronisation entre certaines centrales.
Cette approche permet de tester rapidement plusieurs scénarios stratégiques.
Résultats clés
- Réduction mesurée des coûts de maintenance sous contraintes réalistes
- Comparaison claire entre stratégies coût-minimal et délai-minimal
- Identification des goulots d’étranglement en ressources humaines
Valeur ajoutée
Ce projet démontre comment l’optimisation déterministe peut servir d’outil d’aide à la décision stratégique dans des contextes industriels critiques, où les ressources sont limitées et les conséquences opérationnelles majeures.
Tech: Excel Solver · Gams · IBM Cplex · PowerBi
Optimisation stochastique
Conception de modèles d’optimisation sous incertitude visant à soutenir la prise de décision lorsque les paramètres clés (demande, performance, environnement) ne sont ni déterministes ni parfaitement observables.
Les projets ci-dessous mettent l’accent sur la modélisation probabiliste, l’arbitrage risque–performance et la valeur de l’information.
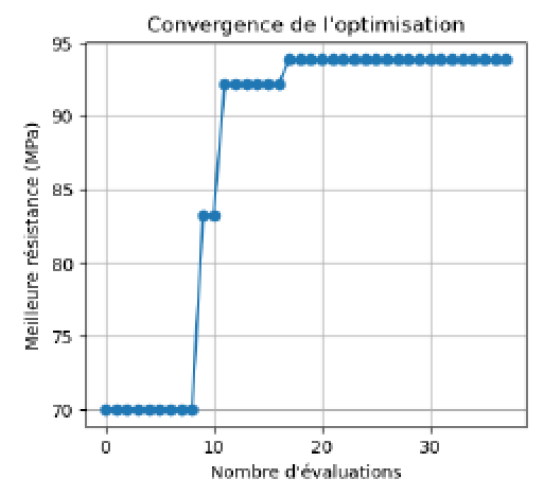
P1 — Optimisation bayésienne pour systèmes expérimentaux coûteux
Contexte
Ce projet traite un problème d’optimisation dans lequel la fonction objectif est inconnue, bruitée et coûteuse à évaluer, situation typique des environnements industriels ou expérimentaux.
Le cas d’étude porte sur l’optimisation de la résistance mécanique d’un polymère, dépendant de paramètres physico-chimiques continus (proportion de plastifiant x₁ ∈ [0,1] et temps de durcissement x₂ ∈ [0,5] heures), pour lesquels chaque évaluation représente un coût réel (temps, ressources, essais en laboratoire).
L’objectif est d’identifier la formulation optimale en minimisant le nombre d’expériences nécessaires, tout en gérant explicitement l’incertitude inhérente aux mesures.
Approche méthodologique
La stratégie repose sur une optimisation bayésienne séquentielle, structurée autour de :
- un modèle substitut probabiliste (processus gaussien) fournissant une estimation de la performance attendue μ(x) et de l’incertitude associée σ(x) à chaque point de l’espace d’entrée,
- une fonction d’acquisition (Expected Improvement) permettant d’équilibrer exploration (zones incertaines) et exploitation (zones prometteuses),
- une mise à jour itérative du modèle à partir de nouvelles observations simulées via la fonction synthétique :
\(f(x_1, x_2) = \sin(3\pi x_1) \cdot (1 - e^{-x_2}) + \epsilon, \quad \epsilon \sim \mathcal{N}(0, 0.1^2)\)
où \(I(x₁,x₂) = -0.5·sin(3πx₁)·cos(2πx₂)\) capture les effets non-linéaires.
Cette approche permet de réduire drastiquement le nombre d’expériences nécessaires (10 itérations vs 100+ par grille exhaustive) tout en convergeant vers des régions prometteuses de l’espace des décisions.
Résultats clés
- Solution optimale identifiée : x₁* = 0.510, x₂* = 2.048 avec une résistance de 93.87 MPa
- Convergence rapide : stabilisation après seulement 10 itérations
- Quantification explicite de l’incertitude associée aux décisions (σ(x) exploité dans la fonction d’acquisition)
- Illustration concrète de la valeur de l’information : chaque observation réduit l’incertitude globale
Valeur ajoutée
Le projet démontre comment l’optimisation stochastique bayésienne constitue une alternative robuste aux méthodes déterministes lorsque les données sont rares, coûteuses ou bruitées, tout en restant interprétable et décisionnelle.
Les applications directes incluent la formulation de matériaux (polymères, alliages, composites), l’optimisation de procédés chimiques, le réglage de paramètres de fabrication, et l’optimisation d’hyperparamètres en machine learning.
Tech : Python · R · NumPy · SciPy · Matplotlib
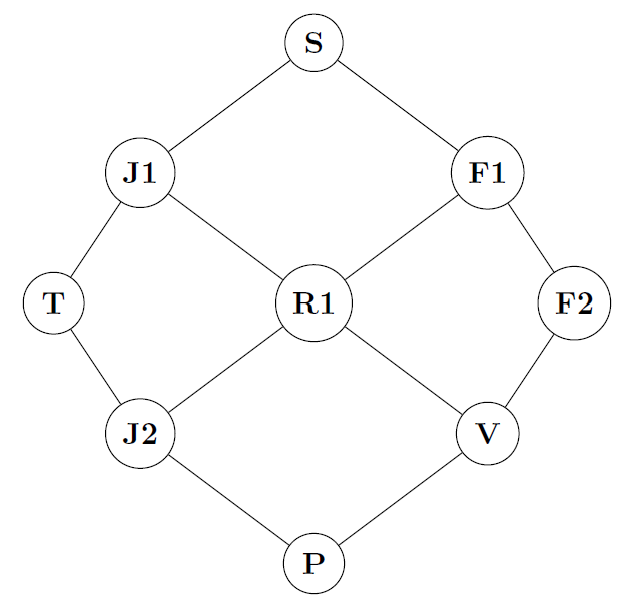
P2 — Décision optimale sous incertitude et scénarios probabilistes
Contexte
Ce projet s’inscrit dans un cadre de prise de décision séquentielle sous risque, où l’issue des actions dépend de transitions probabilistes et de chocs aléatoires.
Le scénario modélisé est celui d’un chasseur de trésors naviguant dans une jungle dense, devant atteindre un temple ancien (récompense +1000) tout en minimisant l’exposition aux scénarios défavorables : falaises (75% succès / 25% chute, pénalité -100), rivières (80% / 20%, -75), jungles (90% / 10%, -50), et états absorbants négatifs (Vallée de la Mort : -150, Prédateurs : -200).
L’objectif est de maximiser la valeur attendue sur l’horizon de décision, tout en gérant explicitement le coût du temps (-10 par action) et l’aversion au risque.
Approche méthodologique
La modélisation repose sur une formulation stochastique explicite sous forme de Processus de Décision Markovien (MDP), intégrant :
- des scénarios probabilistes représentant les issues possibles de chaque décision, avec transitions P(s’|s,a) variant selon le terrain,
- une fonction de valeur attendue V*(s) = max_a Σ_s’ P(s’|s,a)[R(s,a,s’) + γ·V*(s’)] intégrant récompenses, pénalités et coût du temps,
- un facteur d’actualisation γ = 0.9 traduisant la préférence temporelle et l’aversion au risque.
L’analyse inclut à la fois une résolution exacte (Value Iteration, convergence en 13 itérations) et une approximation linéaire de la fonction de valeur via TD Learning, permettant d’étudier les compromis entre précision et complexité computationnelle :
\(V(s) ≈ θ₁·f₁(s) + θ₂·f₂(s) + θ₃·f₃(s)\)
avec f₁ = distance au trésor, f₂ = proximité aux dangers, f₃ = indicateur d’état sûr.
Résultats clés
- Politique optimale exacte identifiée : S→J1→T (valeurs optimales V(S)=1666.37, V(J1)=1862.64)
- Mise en évidence de stratégies évitant les états à forte perte attendue (falaises, rivière)
- Sensibilité marquée au facteur d’actualisation : γ élevé favorise la prise de risque pour le gain final
- Capacité des approximations linéaires (TD Learning, 1000 épisodes) à capturer la structure globale : θ₃=1799.45 (états sûrs valorisés), θ₂=1619.82 (éviter les dangers), θ₁=-48.75 (minimiser distance)
Valeur ajoutée
Ce travail illustre les fondements de l’optimisation stochastique multi-étapes et met en lumière les enjeux centraux de la décision sous incertitude : anticipation, prudence et gestion du risque.
Les applications directes incluent la planification de trajectoires robotiques, la gestion de portefeuille financier (risque/rendement), les stratégies de recherche et sauvetage, l’optimisation logistique sous incertitude, et la navigation autonome.
Tech : Python · R · Pandas · NetworkX · NumPy · Matplotlib
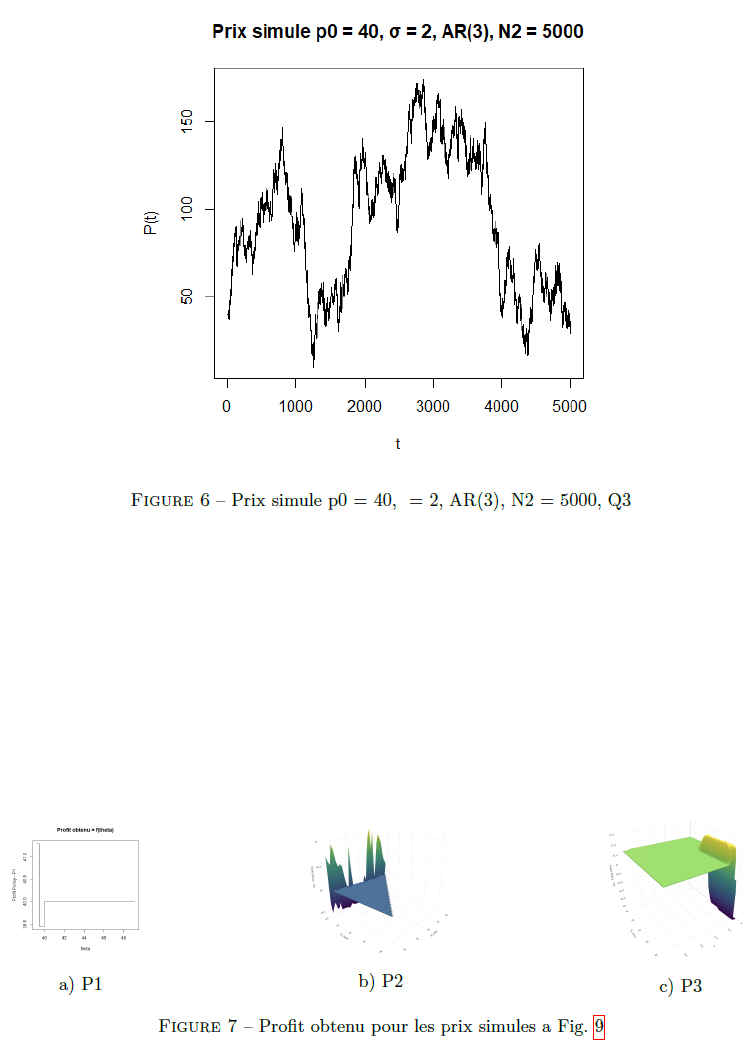
P3 — Politique optimale de vente sous incertitude de prix
Contexte
Problème de pricing dynamique dans un contexte d’incertitude stochastique sur l’évolution future des prix d’un actif.
Un vendeur détient un bien qu’il peut vendre à tout moment. Les prix fluctuent aléatoirement selon différents processus stochastiques (marche aléatoire, modèle autorégressif AR(3)). L’objectif est d’identifier la politique de vente maximisant le profit espéré, en arbitrant entre vente immédiate (exploitation) et attente d’un meilleur prix (exploration).
Approche méthodologique
Trois classes de politiques paramétriques sont comparées via simulation Monte Carlo (1000–5000 réalisations) :
- Politique “vendre-bas” : vendre dès que p_t ≥ θ_bas (règle de seuil simple)
- Politique “haut-bas” : vendre si p_t ≥ θ_haut ou p_t ≤ θ_bas (stop-loss + take-profit)
- Politique “suivi” : vendre si p_t ≥ α·p̄_t + (1-α)·θ_suivi (moyenne mobile adaptative)
Les politiques sont évaluées sous différents modèles stochastiques de prix :
- Marche aléatoire : p_{t+1} = p_t + ε, ε ~ N(0,σ²)
- Modèle AR(3) : p_{t+1} = θ₀·p_t + θ₁·p_{t-1} + θ₂·p_{t-2} + ε (capture l’autocorrélation)
L’optimisation porte sur l’identification des meilleurs paramètres (θ_bas, θ_haut, θ_suivi, α) pour chaque politique et chaque modèle.
Résultats clés
Politique “suivi” systématiquement gagnante sur tous les scénarios testés :
• Marche aléatoire (N=5000) : 45.55$ (vs 45.22$ pour les autres)
• AR(3) avec autocorrélation : 41.59$ (vs 41.28\(–41.59\))Performance stable à travers différents modèles stochastiques (robustesse)
Impact de l’autocorrélation : profits réduits de ~10% sous AR(3) (41$ vs 46$)
Meilleurs paramètres adaptatifs : α ≈ 0.7–0.9 selon le contexte
Valeur ajoutée
Le projet démontre l’importance de politiques adaptatives face à l’incertitude stochastique, et illustre la méthodologie d’évaluation par simulation pour comparer des stratégies décisionnelles.
Les applications directes incluent le trading algorithmique, la gestion de stocks périssables, la tarification dynamique (hôtellerie, transport), les enchères en ligne, et le yield management.
Tech : Python · R · Simulation Monte Carlo · NumPy · Pandas · Matplotlib
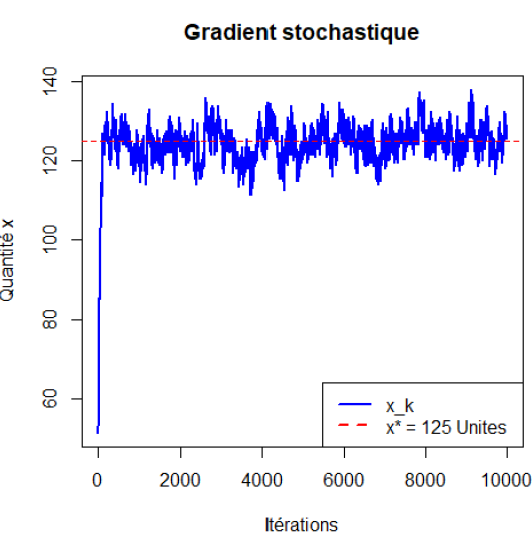
P4 — Gestion optimale d’inventaire sous incertitude de demande
Contexte
Problème classique d’optimisation d’inventaire sous incertitude, étendu pour inclure une valeur de récupération des invendus (prix s par unité, 0 < s < r).
Un vendeur doit déterminer la quantité optimale à commander (x*) avant d’observer la demande aléatoire D, sachant qu’il encourt un coût d’achat c par unité, vend au prix r, et peut récupérer les invendus à un prix s. L’objectif est de maximiser le profit espéré en arbitrant entre risque de pénurie (manque à gagner) et risque de surplus (coût de stockage / dévaluation).
Approche méthodologique
Le problème est formulé comme un modèle d’optimisation stochastique analytique :
\(max_x E[r·min(x,D) + s·max(0,x-D) - c·x]\)
La résolution par calcul du gradient et condition d’optimalité du premier ordre conduit à la formule de quantile critique :
\(x* = F^{-1}(\frac{r-c}{r-s})\)
Deux approches sont comparées :
- Solution stochastique optimale (x* = 125 unités pour D ~ U(50,150), c=10, r=25, s=5)
- Solution déterministe avec demande fixée à E[D] = 100 (x*_det = 100 unités)
L’écart entre les deux quantifie la Valeur de la Solution Stochastique (VSS) : VSS = Π(x) - Π(x_det) = 1100 - 1500 = -400$.
Un algorithme de gradient stochastique est également implémenté pour valider empiriquement la convergence vers x* ≈ 124 unités.
Résultats clés
- Solution optimale analytique : x* = 125 unités (profit espéré 1100$)
- VSS = -400$ : la solution stochastique présente un risque de perte par rapport à une demande déterministe fixée à 100, illustrant l’importance de la qualité des prévisions
- Convergence empirique du gradient stochastique vers x* ≈ 124 unités
- Insensibilité aux bornes de distribution : la formule reste valide pour D ∈ [a,b] avec distribution tronquée
Valeur ajoutée
Ce projet illustre les concepts fondamentaux de l’optimisation stochastique : équilibre coût/bénéfice sous incertitude, valeur de l’information parfaite, et analyse de sensibilité aux paramètres (c, r, s, distribution de D).
Les applications directes incluent la gestion de stocks (retail, manufacturing), la planification de capacité, et toute situation de décision avant observation d’une demande aléatoire.
Tech : Python · R · NumPy · Matplotlib
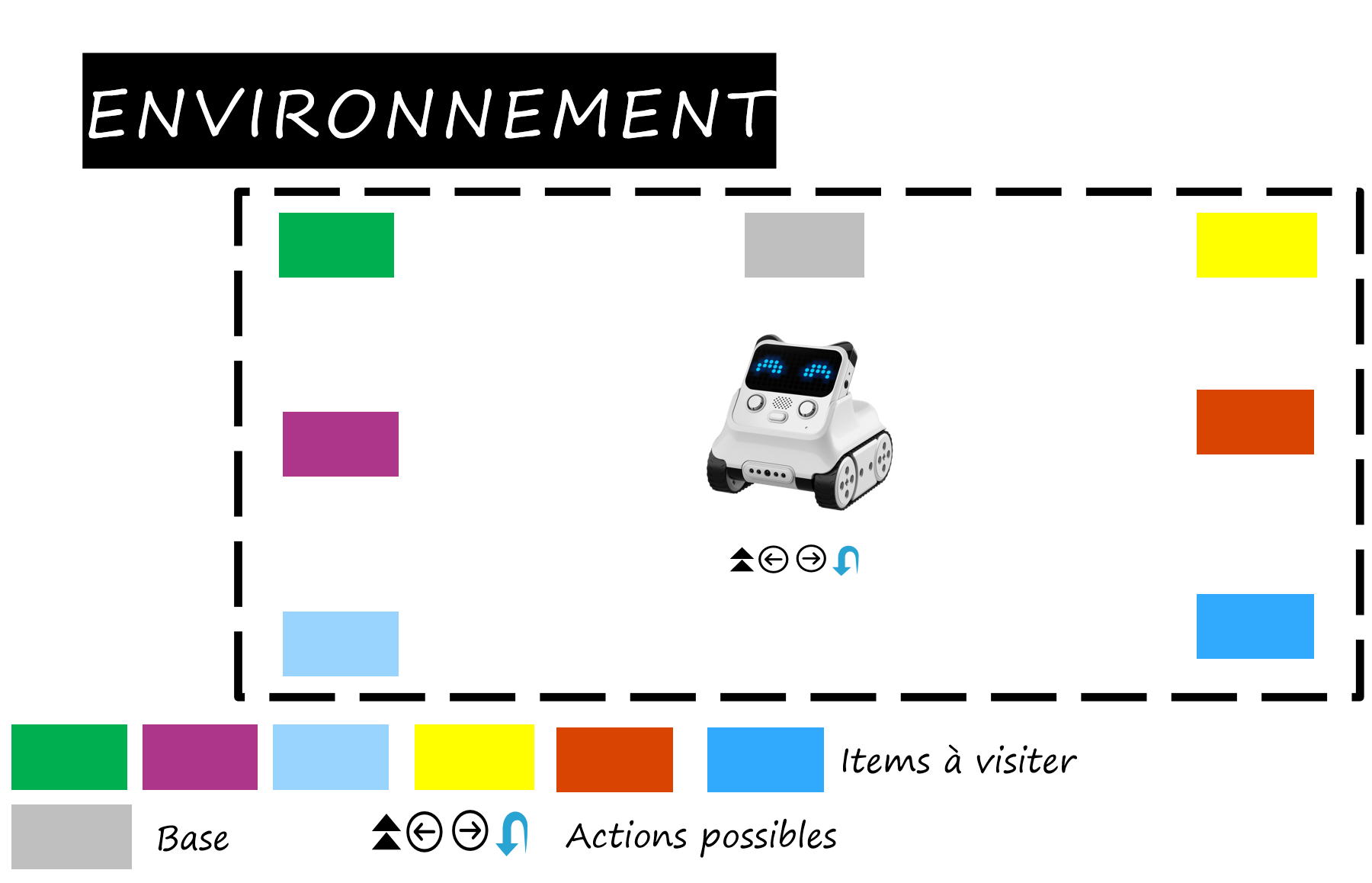
Apprentissage par renforcement
Application de l’apprentissage par renforcement à un problème de contrôle séquentiel et d’optimisation combinatoire, dans un environnement simulé et contraint, avec une implémentation complète en Python natif et des bibliothèques standards de l’écosystème scientifique.
Data Engineering & MLOps
Conception et mise en œuvre de pipelines de données et de modèles IA entièrement déployés en production, avec une attention particulière portée à la scalabilité cloud, à la reproductibilité expérimentale et à l’intégration de paradigmes avancés comme l’apprentissage fédéré.
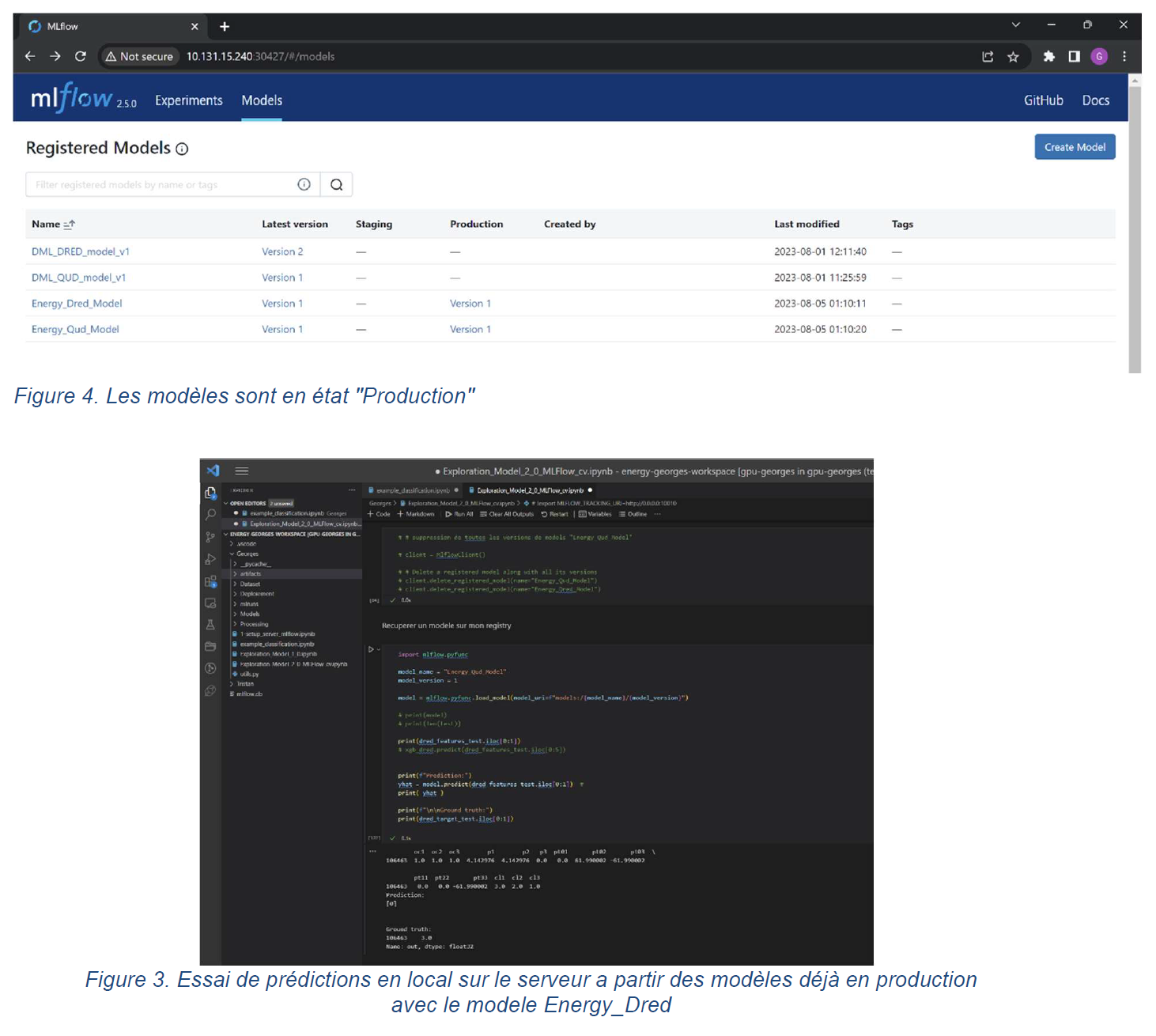
P1 — Plateforme MLOps cloud-native pour la surveillance énergétique intelligente
Contexte
Projet de bout en bout visant la conception d’une plateforme MLOps industrielle déployée intégralement sur le cloud AWS, pour l’analyse et la prévision de la consommation énergétique de systèmes distribués.
Le cadre opérationnel impose des contraintes fortes : données hétérogènes, déploiement multi-sites, sécurité des données et besoin de prédictions en temps réel.
L’objectif est de couvrir l’ensemble du cycle de vie d’une application IA en production, depuis l’ingestion des données jusqu’au serving des modèles, tout en intégrant une approche d’apprentissage fédéré afin de préserver la confidentialité des données locales.
Architecture cloud & déploiement
L’application est déployée de bout en bout sur AWS, avec une architecture orientée services :
Stockage & données
- Données historisées et intermédiaires stockées sur Amazon S3
- Séparation claire entre données brutes, features et artefacts modèles
Calcul & orchestration
- Services conteneurisés orchestrés via AWS Kubernetes (EKS)
- Entraînement et inférence distribués, avec support GPU
- Scalabilité horizontale automatique selon la charge
- Services conteneurisés orchestrés via AWS Kubernetes (EKS)
Serving & intégration
- Modèles exposés via endpoints API
- Déclenchements asynchrones via AWS Lambda pour l’inférence et les mises à jour
- Architecture prête pour des usages temps réel et batch
- Modèles exposés via endpoints API
MLOps & expérimentation
- Suivi des expériences, des métriques et des versions de modèles
- Gestion des statuts (expérimentation, validation, production)
- Séparation stricte entre pipelines data, entraînement et déploiement
Apprentissage fédéré (élément clé)
Un mécanisme d’apprentissage fédéré a été mis en œuvre afin de :
- Entraîner des modèles sans centraliser les données sensibles
- Agréger les poids appris localement sur différents nœuds
- Réduire les risques liés à la confidentialité et à la gouvernance des données
- Simuler des scénarios industriels multi-sites (bâtiments, régions, équipements)
Cette approche constitue un levier novateur pour les systèmes énergétiques et industriels, où les contraintes réglementaires et opérationnelles limitent la centralisation des données.
Résultats clés
- Application IA entièrement déployée en production sur AWS
- Pipeline MLOps fonctionnel du stockage à l’API de prédiction
- Validation du fonctionnement en environnement distribué
- Intégration réussie de l’apprentissage fédéré dans une architecture cloud
Valeur ajoutée
Ce projet démontre une maîtrise avancée du Data Engineering et du MLOps cloud-native, ainsi qu’une capacité à intégrer des paradigmes de recherche récents (federated learning) dans des architectures industrielles réalistes.
Il illustre le passage complet de la modélisation à l’industrialisation, avec une vision système et long terme.
Tech : AWS (S3, Lambda, EKS, Endpoints) · Fast Api · Nginx · Data Engineering · MLOps · Docker · Kubernetes · GPU Computing · Federated Learning
Traitement du langage naturel (NLP) & LLM
Analyse avancée de corpus textuels à grande échelle afin d’extraire des structures sémantiques latentes, comparer des discours médiatiques internationaux et comprendre l’évolution des narratifs dans le temps.

P1 — Analyse comparative de discours médiatiques internationaux (COVID-19)
Contexte
Projet académique de grande envergure mené à HEC Montréal visant à analyser et comparer les discours médiatiques anglophones provenant de plusieurs pays et continents autour d’une thématique commune : la pandémie de COVID-19.
L’objectif est d’identifier comment un même événement global est traité différemment selon les contextes géopolitiques, culturels et temporels, au-delà du simple contenu factuel.
Approche méthodologique
La démarche repose sur une chaîne complète de traitement automatique du langage naturel, combinant :
- une analyse exploratoire approfondie des textes (longueur, distribution temporelle, provenance géographique),
- un prétraitement linguistique rigoureux (nettoyage, normalisation des entités, gestion des variantes lexicales, réduction du bruit),
- une modélisation thématique non supervisée (Topic Modeling) permettant d’extraire les sujets dominants sans hypothèses a priori.
L’analyse est structurée par périodes temporelles clés (début, pic et phase tardive de la pandémie), afin d’étudier l’évolution des narratifs médiatiques dans le temps.
Résultats clés
- Mise en évidence de thématiques distinctes selon les phases de la pandémie (réaction initiale, politiques publiques, impacts socio-économiques, variants, assouplissement des mesures)
- Différences marquées entre régions dans la priorisation des sujets (santé publique, gouvernance, économie, société)
- Capacité du Topic Modeling à révéler des dynamiques discursives latentes, difficilement observables par lecture manuelle
Défis et enseignements
- Forte hétérogénéité des sources (styles rédactionnels, tailles d’articles, vocabulaire)
- Importance critique du prétraitement et de la normalisation linguistique pour obtenir des résultats exploitables
- Nécessité d’un arbitrage constant entre richesse sémantique et stabilité statistique des modèles
Valeur ajoutée
Ce projet démontre une maîtrise avancée des techniques NLP modernes, avec une capacité à transformer des textes non structurés en indicateurs analytiques interprétables, utiles pour : - l’analyse médiatique,
- la veille stratégique,
- la recherche en sciences sociales et décisionnelles.
Il constitue également une base solide pour des extensions vers l’analyse de sentiment, les modèles de langage de grande taille (LLM) et l’étude fine des dynamiques narratives multi-pays.
Tech : NLP · Topic Modeling · Text Mining · SpaCy · Gensim · NLTK · Transformers · Visualisation sémantique
Appprentissage machine et profond & Vision par ordinateur
Application de techniques avancées d’apprentissage machine et profond à des problématiques réelles de classification, modélisation spatiale et analyse prédictive, avec un focus sur l’interprétabilité et la robustesse des modèles.
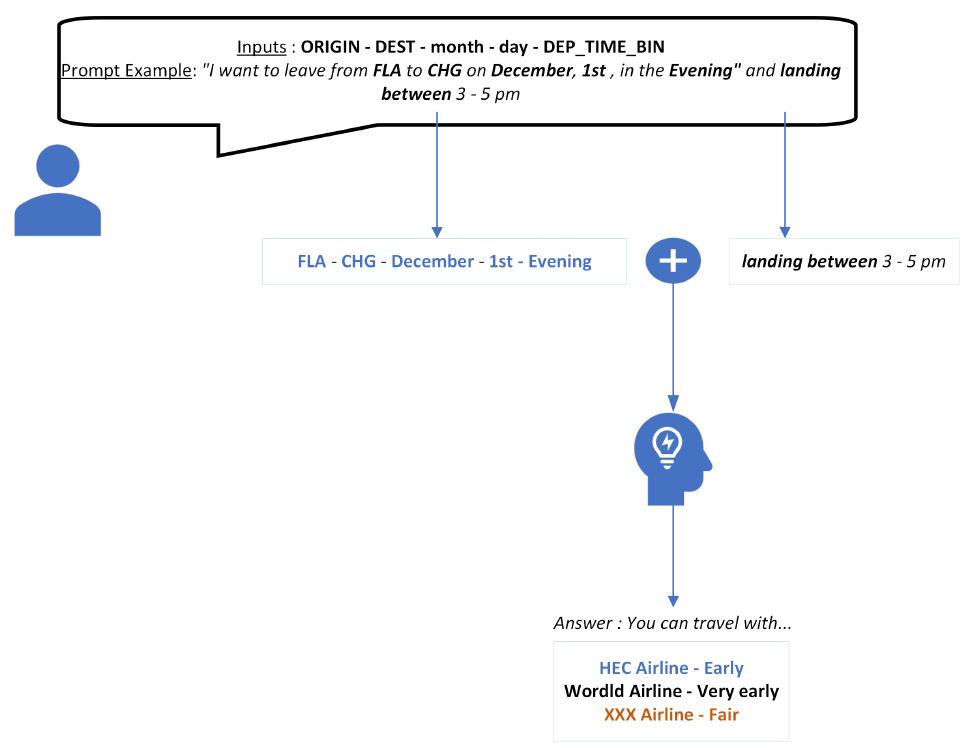
P1 — Prédiction de la fiabilité des compagnies aériennes pour les trajets commerciaux
Contexte
Projet de modélisation prédictive visant à estimer la fiabilité des compagnies aériennes pour des trajets donnés, à partir d’un vaste historique de vols commerciaux nord-américains.
La fiabilité est définie de manière opérationnelle à partir de critères combinant retards, annulations et variabilité temporelle, dans un contexte où les décisions des usagers sont fortement sensibles à l’incertitude.
L’objectif est de fournir une aide à la décision robuste, permettant de comparer les compagnies aériennes selon le risque associé à un trajet spécifique, en tenant compte du contexte spatio-temporel.
Approche de modélisation
La démarche repose sur une modélisation supervisée structurée :
- Formalisation du problème comme une prédiction de classes de fiabilité (faible, moyenne, élevée)
- Intégration de variables temporelles, géographiques et opérationnelles
- Comparaison de plusieurs familles de modèles de classification
- Analyse des compromis entre précision globale, stabilité et interprétabilité
- Évaluation rigoureuse dans un cadre respectant la structure temporelle des données
Une attention particulière est portée au déséquilibre des classes et à l’impact de celui-ci sur la qualité des prédictions.
Résultats clés
- Capacité à différencier clairement les niveaux de fiabilité selon les compagnies et les trajets
- Mise en évidence de facteurs temporels et géographiques dominants
- Amélioration significative par rapport aux approches naïves de classement
- Modèles stables et cohérents sur des périodes hors échantillon
Valeur ajoutée
Ce projet illustre une application concrète de la modélisation prédictive à grande échelle, avec un fort lien entre statistique, apprentissage automatique et prise de décision utilisateur.
Il met en avant la capacité à transformer des données massives en indicateurs de fiabilité exploitables.
Tech : Apprentissage supervisé · Classification · Modélisation prédictive · Évaluation sous déséquilibre · Python · Scikit-learn · XGBoost · Pandas · Matplotlib
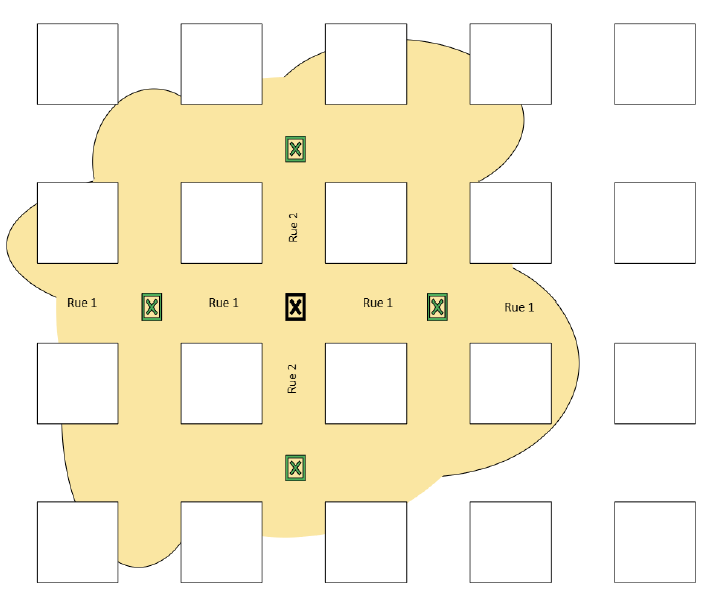
P2 — Modélisation spatiale du risque d’accidents aux carrefours de Montréal
Contexte
Projet appliqué à la sécurité routière urbaine, visant à modéliser et classer le niveau de risque d’accidents aux carrefours de la ville de Montréal.
Les accidents de la route présentent une dépendance spatiale forte : des carrefours proches partagent souvent des caractéristiques communes liées à l’environnement urbain, au trafic et à l’infrastructure.
L’objectif est de produire un classement robuste des carrefours selon leur dangerosité, afin de soutenir les décisions en matière d’aménagement et de prévention.
Approche de modélisation
La démarche combine modélisation statistique et dépendance spatiale :
- Modélisation du nombre d’accidents via des modèles de comptage adaptés
- Introduction de variables spatiales décalées (lags spatiaux)
- Construction de structures de voisinage (distance, rayon, k-plus proches voisins)
- Comparaison de modèles :
- modèles classiques de comptage,
- modèles à effets aléatoires,
- modèles spatiaux intégrant explicitement la dépendance géographique
L’évaluation repose sur des métriques quantitatives et sur la stabilité du classement des carrefours.
Résultats clés
- Amélioration nette des performances grâce à l’intégration de la dépendance spatiale
- Identification de zones urbaines à risque élevé
- Classement cohérent et interprétable des carrefours
- Résultats directement exploitables pour la planification urbaine
Valeur ajoutée
Ce projet démontre une maîtrise avancée de la modélisation spatiale appliquée, à l’interface entre apprentissage automatique, statistiques et données urbaines.
Il met en évidence la valeur ajoutée de modèles structurels pour des problèmes à fort impact sociétal.
Tech : Modélisation spatiale · Statistiques de comptage · Apprentissage statistique · Données géographiques

P3 — Modélisation de la sollicitation du réseau BIXI à Montréal
Contexte
Projet appliqué à la mobilité urbaine, visant à analyser et modéliser la durée et l’intensité des trajets BIXI à Montréal, à partir de données issues de multiples stations réparties sur le territoire urbain.
Les observations présentent une structure hiérarchique naturelle : les trajets sont imbriqués dans des stations, elles-mêmes situées dans différents arrondissements, ce qui induit des corrélations intra-station significatives.
L’objectif est de comprendre comment la sollicitation du réseau varie selon le contexte spatial et temporel, et de quantifier l’hétérogénéité entre stations.
Approche de modélisation
La démarche repose sur une modélisation statistique progressive :
- Modélisation de base via un modèle linéaire global, intégrant des covariables temporelles (jour de semaine vs fin de semaine)
- Mise en évidence des limites de l’hypothèse d’indépendance des observations
- Introduction de modèles à effets mixtes, avec :
- ordonnées à l’origine aléatoires par station,
- puis effets aléatoires conditionnels à la fin de semaine,
- ordonnées à l’origine aléatoires par station,
- Tests statistiques formels (rapports de vraisemblance, tests de Wald) pour évaluer :
- la significativité des effets aléatoires,
- la variabilité inter-stations,
- la pertinence des structures hiérarchiques.
- la significativité des effets aléatoires,
Une attention particulière est portée à l’estimation et à l’interprétation de la corrélation intra-station, indicateur clé de la dépendance des trajets.
Résultats clés
- Mise en évidence d’une corrélation intra-station élevée, invalidant l’hypothèse d’indépendance
- Variabilité significative de la durée moyenne des trajets entre arrondissements
- Effet global positif de la fin de semaine sur la durée des trajets
- Faible variabilité inter-stations de l’effet « fin de semaine », justifiant un modèle plus parcimonieux
Valeur ajoutée
Ce projet démontre une maîtrise avancée des modèles hiérarchiques et des effets mixtes, essentiels pour l’analyse de données urbaines corrélées.
Il met en évidence l’importance d’une modélisation structurelle adaptée pour éviter des conclusions biaisées dans les systèmes de mobilité partagée.
Tech : Modèles linéaires mixtes · Statistiques avancées · Données de mobilité urbaine · Analyse hiérarchique · R · lme4 · ggplot2